Converter fala em texto nunca foi tão fácil, graças aos modelos de fala para texto do Hugging Face. Quer você esteja transcrevendo entrevistas, gerando legendas ou desenvolvendo aplicativos com tecnologia de IA, o Hugging Face fornece reconhecimento de fala de última geração, alimentado por modelos avançados de aprendizado de máquina. A melhor parte? É altamente personalizável, permitindo que você ajuste modelos para melhor precisão e desempenho com base em suas necessidades específicas.
Neste guia, mostraremos como configurar e usar a API de conversão de fala para texto do Hugging Face, explorar suas opções de personalização e discutir casos de uso prático. Mas e se você precisar de uma alternativa mais simples? Não se preocupe, também apresentaremos uma ferramenta de conversão de fala para texto fácil de usar que realiza o trabalho sem esforço. Seja você um desenvolvedor, criador de conteúdo ou profissional de negócios, este guia ajudará você a encontrar a melhor solução de conversão de fala em texto para seu fluxo de trabalho. Continue lendo.
Neste artigo
Parte 1: Como funciona a conversão de fala para texto do Hugging Face
A Conversão de Fala para Texto do Hugging Face é um ótimo recurso da biblioteca Hugging Face Transformers que permite transformar palavras faladas em texto escrito usando modelos pré-treinados. Usa tecnologia avançada de reconhecimento automático de fala (ASR) para transcrever a fala. Com arquiteturas baseadas em transformadores como Wav2Vec2, o sistema processa dados de áudio e os converte em texto. E faz isso com grande precisão.
Uma das coisas que faz a Conversão de Fala para Texto do Hugging Face se destacar é sua integração de pipeline, o que o torna muito fácil para desenvolvedores. Com apenas algumas linhas de código, você pode processar arquivos de áudio e obter transcrições de texto. Além disso, ele possui modelos pré-treinados para vários idiomas e cenários de fala, por isso é adaptável para muitos casos de uso.
O processo de conversão de fala para texto segue uma sequência passo a passo para garantir uma transcrição precisa:
- Entrada de áudio: Você fornece um arquivo de áudio para processar.
- Extração de recursos: O sistema extrai recursos de fala e bancos de filtros log-mel. Isso ajuda a analisar padrões sonoros.
- Inferência de modelo: Um modelo de transformador pré-treinado processa os recursos e gera tokens de texto que representam palavras faladas.
- Saída de texto: O modelo converte esses tokens em uma transcrição de texto.
Os modelos de conversão de fala para texto do Hugging Face, particularmente o SeamlessM4T-v2, melhoram a eficiência ao implementar uma estrutura de sequência dupla para sequência (seq2seq). Possui codificadores de fala e texto separados, bem como um vocoder HiFi-GAN, que melhora a qualidade da voz gerada. Esta é uma ferramenta útil para reconhecimento e automação de fala, com aplicativos que incluem assistentes virtuais, legendas ao vivo, serviços de transcrição e pesquisa por voz.
Parte 2: Configurando o recurso de fala para texto do Hugging Face
Abaixo está um guia passo a passo sobre como configurar para usar o recurso de fala para texto do Hugging Face:
Passo 1: Crie uma conta no Hugging Face
A primeira coisa que você precisa é de uma conta no Hugging Face. Criar uma conta lhe dá acesso a modelos e APIs pré-treinados. Se você ainda não tem uma conta;
- Acesse o site do Hugging Face
- Clique em Registrar-se
- Insira seus dados e crie uma conta
- Depois de iniciar sessão, vá para as Configurações do seu perfil
- Encontre os tokens de acesso e crie um novo token (escolha "Gravar" como nível de permissão)
Este token ajudará você a se conectar ao Hugging Face a partir do seu código.
Passo 2: Instale as bibliotecas necessárias
A próxima coisa que você precisa fazer é instalar todas as bibliotecas que você precisa. Para fazer isso, abra seu terminal ou prompt de comando e digite:
| pip install transformers datasets torchaudio librosa soundfile |
Transformers serve para carregar modelos Hugging Face, torchaudio ajuda a processar dados de áudio, enquanto librosa e soundfile ajudam a carregar e modificar arquivos de áudio.
Passo 3: Carregue o modelo
Depois de instalar todas as bibliotecas necessárias, a próxima coisa que você precisa fazer é carregar o modelo de conversão de fala para texto. Você pode usar o Wav2Vec2, pois é um dos melhores modelos pré-treinados para reconhecimento de fala.
|
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor import torch
# Carregue o modelo e o processador model_name = "facebook/wav2vec2-large-960h" processor = Wav2Vec2Processor.from_pretrained(model_name) model = Wav2Vec2ForCTC.from_pretrained(model_name) |
Passo 4: Converta o áudio em texto
Você precisa preparar seu arquivo de áudio para que o modelo possa entendê-lo. Para fazer isso, você precisa carregar o áudio no seu software. Depois, certifique-se de que esteja no formato correto para que o modelo possa processá-lo adequadamente. Você o executará no modelo para transformar a fala para texto.
|
import librosa
# Carregue um arquivo de áudio e converta para 16 kHz def load_audio(file_path): audio, sr = librosa.load(file_path, sr=16000) return audio
audio_file = "example.wav" audio_input = load_audio(audio_file) |
Processe a entrada de áudio para que o modelo possa lê-la
| input_values = processor(audio_input, return_tensors="pt", sampling_rate=16000).input_values |
Como personalizar modelos de conversão de fala para texto
Se você quer que seu modelo de rosto abraçado para conversão de fala em texto funcione melhor, você precisa ajustá-lo. O modelo básico é bom, mas pode não entender certos sotaques, ruídos de fundo ou palavras especiais. Treiná-lo com seus próprios dados o ajuda a aprender e melhorar, tornando-o muito mais preciso para suas necessidades. Veja como você pode ajustar o modelo:
- Ajuste fino com dados personalizados: Treine o modelo com seus próprios conjuntos de dados de áudio e transcrição para melhorar o reconhecimento de sotaques específicos ou termos do setor.
- Ajuste as configurações de inferência: Modifique parâmetros como temperatura e busca de feixe para refinar a precisão.
- Adicione vocabulário personalizado: Ensine ao modelo novas palavras e frases relevantes ao seu domínio.
A personalização torna o modelo mais preciso e confiável para suas necessidades específicas. Mas se você preferir uma solução mais simples, confira a próxima seção para uma alternativa fácil à conversão de fala para texto!
Parte 3: Uma alternativa mais fácil: Conversão automática de fala para texto com Filmora
A Conversão de Fala para Texto do Hugging Face parece muito complicado e requer habilidades técnicas como codificação. Mas há uma alternativa mais fácil: O Wondershare Filmora é uma abordagem muito mais simples para converter fala para texto. O Filmora é um software popular de edição de vídeo que possui uma ferramenta de conversão de fala para texto que transcreve áudio automaticamente com apenas alguns cliques.
- O Filmora simplifica tudo para você. Portanto, você não precisa de habilidades de programação ou configurações complexas.
- Consegue transcrever fala em vídeo para texto com até 99% de precisão. Assim, criadores de conteúdo, estudantes e até mesmo profissionais de negócios podem usá-lo para gerar texto a partir de áudio de forma rápida e precisa.
- Suporta mais de 45 idiomas e funciona bem para legendas de vídeo, notas de voz e entrevistas.
- Está equipado com tradução automática de legendas para conteúdo multilíngue.
- Você pode gerar legendas animadas personalizáveis para aumentar o engajamento.
- Além disso, o recurso de conversão de fala para texto integrado do Filmora processa dados de áudio muito rapidamente e poupa tempo para o usuário. Sua velocidade e capacidade de poupar tempo são o que o tornam a melhor alternativa.
Parte 4: Como usar a Conversão de Fala para Texto do Filmora
O Filmora torna muito simples converter fala para texto. Não há necessidade de criar código nem configurar nada difícil.
Basta seguir estas instruções simples para obter sua transcrição rapidamente usando o recurso de conversão de fala para texto no computador:
Passo 1: Importe seu áudio ou vídeo
Abra o Filmora e adicione seu arquivo de áudio ou vídeo. Você pode fazer isso simplesmente arrastando e soltando na linha do tempo. Isso torna tudo mais fácil para você. Depois que seu arquivo estiver pronto, você estará pronto para prosseguir.

 transferência segura
transferência segura

Passo 2: Selecione a opção de Conversão de Fala para Texto
Vá até Ferramentas na barra de menu superior e clique nela. Selecione a opção Áudio e depois Texto para Fala para analisar seu áudio automaticamente. Não é necessário ajustar as configurações nem fazer nada extra, pois ele cuida de tudo para você.
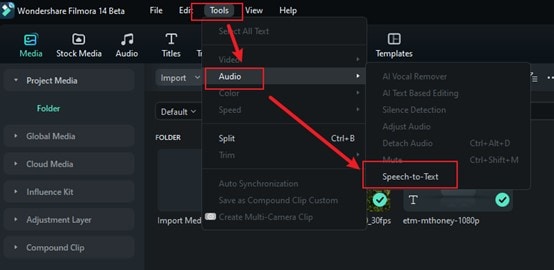
Passo 3: Escolha seu idioma
O Filmora suporta muitos idiomas, então escolha aquele que corresponde ao seu áudio. Este passo é importante porque escolher o idioma certo ajuda o Filmora a transcrever seu discurso com precisão. Se você pular isso, poderá obter alguns resultados incorretos.
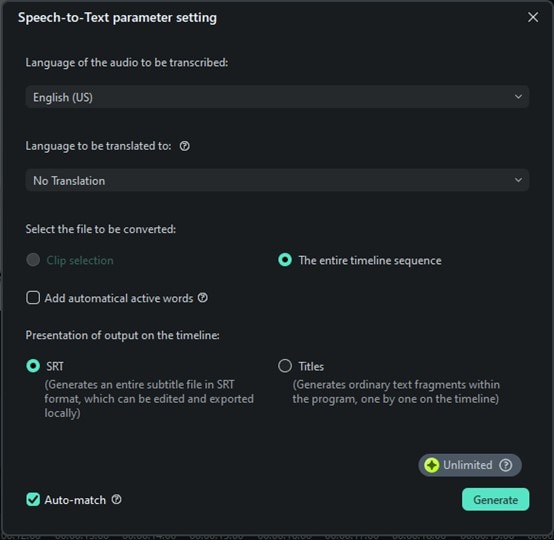
Passo 4: Inicie a transcrição e salve
Agora, basta clicar em Gerar, e o Filmora começará a transcrever seu discurso. Essa parte é muito rápida. Em segundos, você verá as palavras faladas aparecerem como texto. Sem espera de horas, sem configuração complexa, apenas resultados instantâneos. Clique no arquivo de texto, selecione Exportar Transcrição do Arquivo de Legenda para salvá-lo e adicioná-lo como legenda ao seu vídeo.
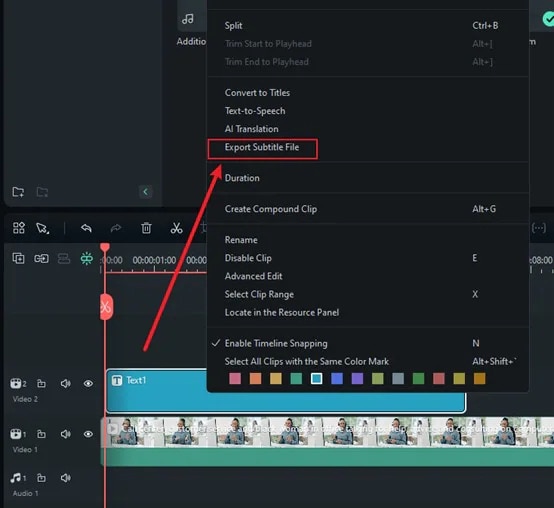
Se você quiser converter fala de vídeo em legendas de texto, o Filmora também oferece um recurso de Legendas de IA em seu aplicativo móvel. Permite gerar legendas de texto no seu dispositivo móvel em menos de um minuto
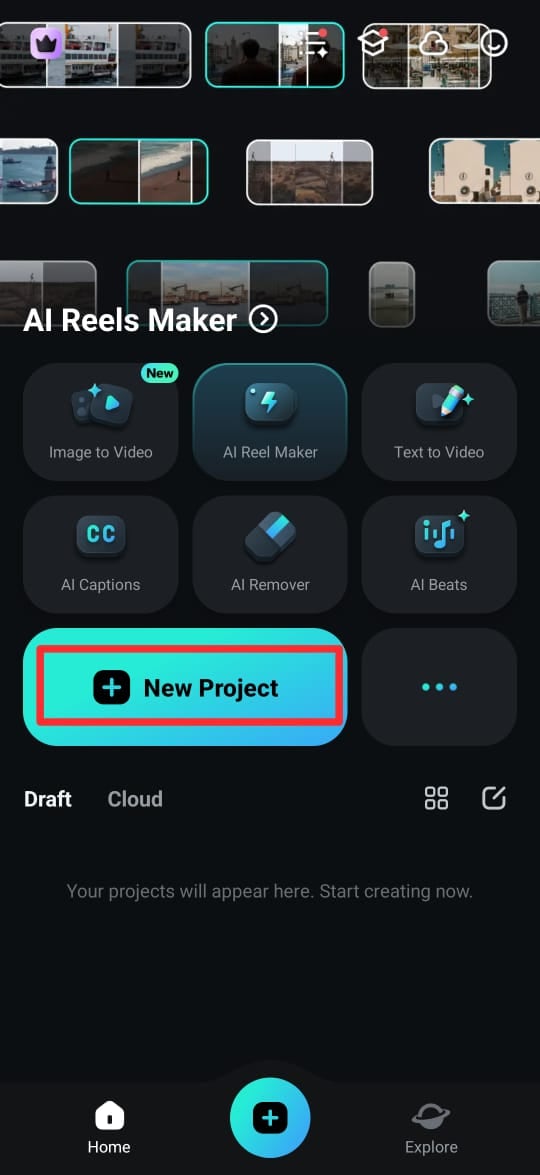
Passo 1: Baixe o aplicativo Filmora na Google Play Store (Android) ou App Store (iPhone). Você também pode obtê-lo no site oficial. Após a instalação, abra o aplicativo e toque em Novo Projeto.
 transferência segura
transferência segura Passo 2. Escolha um vídeo da sua biblioteca de mídia e toque em Importar para adicioná-lo ao seu espaço de trabalho.

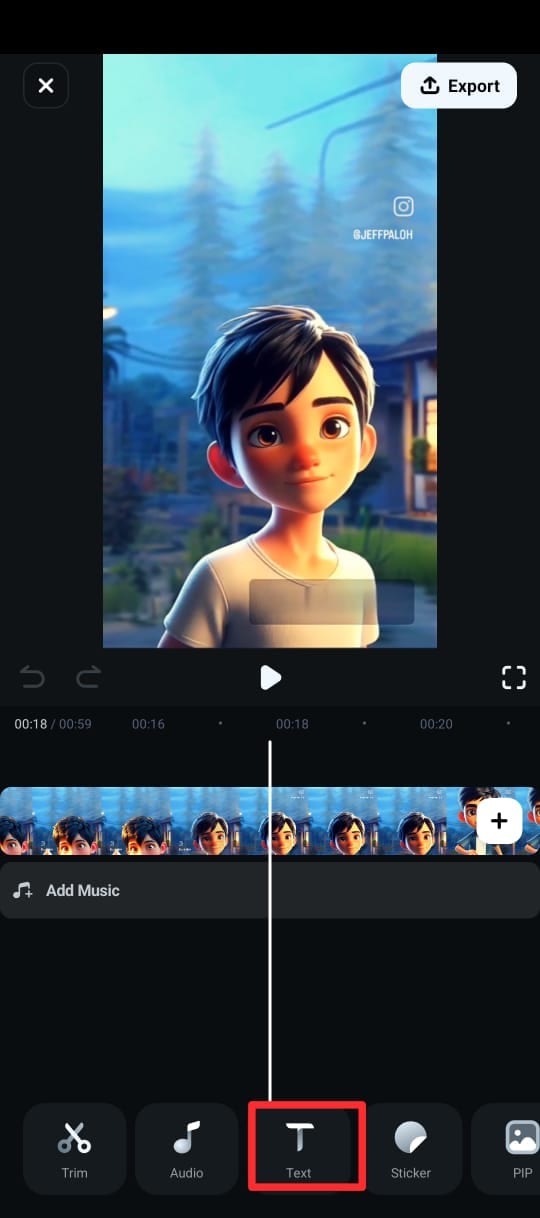
Passo 3: No menu inferior, toque em Texto (marcado por um ícone T) e escolha Legendas de IA.
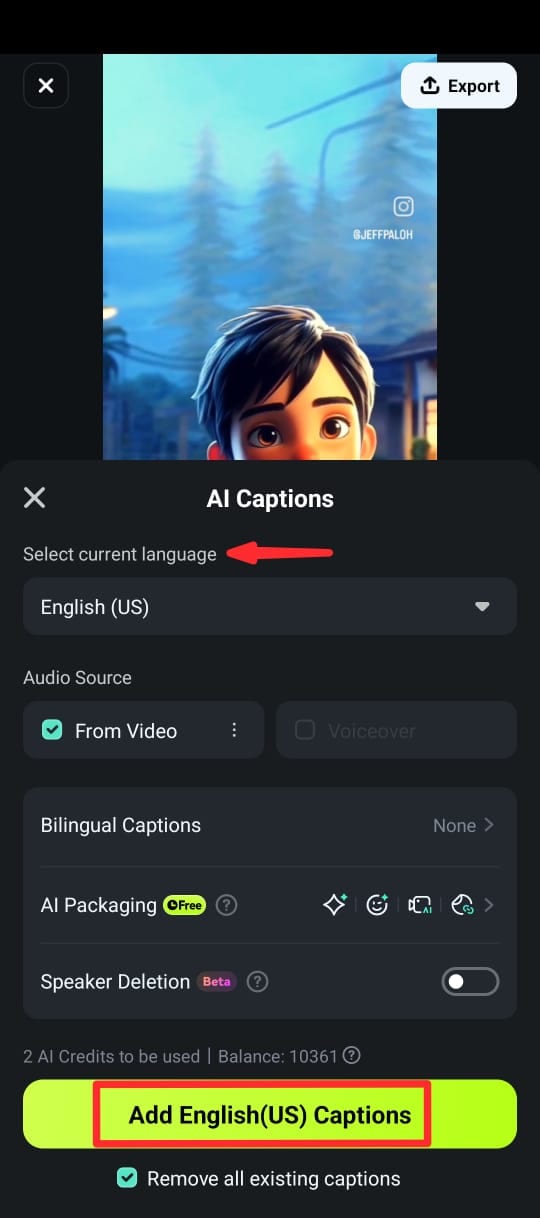
Passo 4: Na próxima tela, selecione o idioma, ative a Detecção de Locutor e toque em Adicionar Legendas para gerar texto a partir da fala do vídeo.
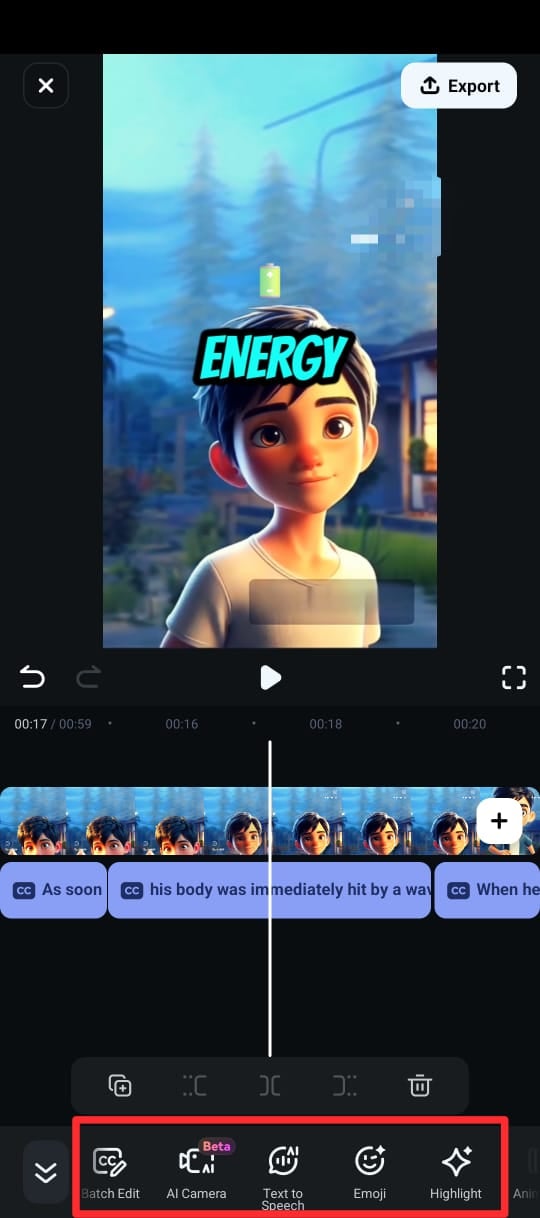
Passo 5: Depois que as legendas forem geradas, você pode personalizar o texto usando diferentes modelos de texto, emojis e fontes. Você também pode editar o texto do clipe na linha do tempo selecionando Editar Fala no conjunto de edição.
Passo 6: Exporte seu vídeo com legendas no formato desejado.
Parte 5. Qual ferramenta é a melhor?
A escolha entre Hugging Face e Filmora depende de suas necessidades específicas e nível de conhecimento técnico. Cada ferramenta atende a um propósito diferente, então vamos explorar qual é a certa para você com base em diferentes cenários.
- Se você precisa de personalização avançada e controle com tecnologia de IA, o Hugging Face fala para texto é a melhor escolha. É ideal para desenvolvedores, pesquisadores e profissionais que desejam treinar modelos, ajustar parâmetros e trabalhar com grandes conjuntos de dados. No entanto, exige conhecimento de codificação e tempo para ser configurado, o que o torna menos adequado para iniciantes ou para aqueles que buscam uma solução rápida.
- Por outro lado, se você quer uma ferramenta de transcrição rápida e precisa, sem nenhuma configuração técnica, o Filmora é o caminho certo. Foi desenvolvido para criadores de conteúdo, estudantes e profissionais que precisam de uma solução simples, com apenas um clique.
- Use o Filmora se estiver adicionando legendas/legendas ocultas a vídeos, transcrevendo palestras ou convertendo fala para texto para relatórios.
- Para aqueles que trabalham em nichos de mercado que exigem reconhecimento de fala específico de domínio, o Hugging Face permite treinar o modelo em terminologia específica do setor. Isso garante maior precisão para jargões complexos, mas, novamente, exige esforço e conhecimento técnico.
- Enquanto isso, se seu objetivo principal é transcrever conteúdo de vídeo, o Filmora é uma opção mais conveniente, pois converte rapidamente fala para texto, tornando-o ideal para YouTubers, podcasters e criadores de mídia social.
Em resumo, se você ama codificação e quer controle total e personalização, opte pela conversão de texto em fala no Hugging Face. Mas se você quer uma ferramenta de transcrição fácil e instantânea, o Filmora é a escolha perfeita. Escolha aquele que melhor se adapta ao seu fluxo de trabalho e nível de habilidade.
Conclusão
Converter fala para texto não precisa ser complicado. A Conversão de Fala para Texto do Hugging Face é uma ferramenta poderosa, mas requer codificação e configuração, o que é ótimo para desenvolvedores. No entanto, se você quer algo rápido e fácil, o Filmora é a melhor alternativa. Com apenas alguns cliques, você pode transcrever áudio sem esforço; sem codificação, sem estresse. Por que gastar horas em configurações complexas? Experimente o recurso de Conversão de Fala para Texto do Filmora hoje mesmo e converta seu áudio em texto em segundos