Transformar palavras faladas em texto com o reconhecimento de fala do Raspberry Pi abre infinitas possibilidades — desde a criação de projetos controlados por voz até a automatização de tarefas. Mas muitos têm dificuldades para configurá-lo, escolher o software certo e melhorar a precisão da transcrição.
Este guia simplificará o processo, mostrando como converter fala em texto no Raspberry Pi passo a passo. Você aprenderá sobre as melhores bibliotecas de reconhecimento de fala, como configurar seu dispositivo e como refinar transcrições para melhor legibilidade. Além disso, apresentaremos uma solução mais fácil para obter resultados de conversão de fala para texto em minutos. Seja você um iniciante ou um usuário avançado, este artigo lhe fornecerá tudo o que você precisa para fazer o reconhecimento de voz do Raspberry Pi funcionar perfeitamente. Vamos começar!

Neste artigo
Parte 1. Visão geral do reconhecimento de fala do Raspberry Pi
A tecnologia de reconhecimento de fala permite que as máquinas entendam e processem a fala humana, convertendo palavras faladas em texto ou comandos. Embora o Raspberry Pi ofereça uma plataforma acessível e flexível para reconhecimento de fala, ele requer configuração manual, hardware específico e conhecimento de bibliotecas de software. Mas quão eficaz é no uso no mundo real? Vamos dar uma olhada em suas capacidades, limitações e desempenho.
Como funciona o reconhecimento de fala no Raspberry Pi
O Raspberry Pi processa a entrada de voz capturando áudio por meio de um microfone, analisando a fala usando software e APIs e convertendo-a em texto ou executando comandos. Normalmente, ele funciona por meio de métodos de reconhecimento baseados em nuvem (Google Speech API) ou offline (CMU Sphinx, Vosk). Aqui está o fluxo de trabalho de reconhecimento de voz do Raspberry:
- Entrada de voz: Um microfone captura o comando falado.
- Processamento: O software de reconhecimento de fala traduz o áudio em texto.
- Execução: Se o texto corresponder a um comando predefinido, o sistema responde adequadamente.
Vantagens do reconhecimento de fala do Raspberry Pi
- Solução acessível – O Raspberry Pi é econômico quando comparado a dispositivos de IA de ponta.
- Altamente personalizável – Os usuários podem escolher entre várias bibliotecas e APIs de reconhecimento de fala.
- Funciona com IoT e robótica – Ideal para projetos de automação residencial e IA.
- Suporta processamento offline – Algumas bibliotecas (CMU Sphinx, Vosk) funcionam sem internet.
Requisitos de hardware para reconhecimento de fala
Para ativar o reconhecimento de fala no Raspberry Pi, você precisa:
- Uma placa Raspberry Pi (Pi 3, 4 ou mais recente para melhor desempenho).
- Um microfone USB ou um fone de ouvido para capturar entrada de voz.
- Uma conexão de Internet estável (se estiver usando reconhecimento de fala baseado em nuvem) – Necessária para Google Speech API, OpenAI Whisper, etc.
- Um cartão microSD com sistema operativo Raspberry Pi instalado.
Embora microfones integrados em alguns modelos de Raspberry Pi possam funcionar, um microfone USB externo melhora a precisão e a clareza.
Software e bibliotecas para reconhecimento de fala no Raspberry Pi
O reconhecimento de fala no Raspberry Pi pode ser feito usando muitas ferramentas de software. As seguintes bibliotecas e APIs de código aberto são frequentemente usadas para reconhecimento de fala no Raspberry Pi:
| Biblioteca/API | Processamento | Conexão de Internet | Precisão e desempenho |
| CMU Sphinx | Offline | ⭐⭐ (Precisão básica) | |
| Vosk | Offline | ⭐⭐⭐ (Melhor precisão) | |
| Mozilla DeepSpeech | Offline | ⭐⭐⭐⭐ (Modelo baseado em IA) | |
| Google Speech API | Baseado em nuvem | ⭐⭐⭐⭐⭐ (Alta precisão) | |
| Picovoice | Offline | ⭐⭐⭐⭐ (Otimizado para dispositivos pequenos) | |
| OpenAI Whisper | Baseado em nuvem | ⭐⭐⭐⭐⭐ (Com tecnologia de IA avançada) |
Parte 2. Como configurar o reconhecimento de fala no Raspberry Pi
Configurar o reconhecimento de fala no Raspberry Pi requer a instalação do software correto, a configuração de um microfone e a execução de um programa de conversão de fala para texto. Siga este guia passo a passo para começar.
Passo 1: Configure o Raspberry Pi
- Instale o SO Raspberry Pi em um cartão SD.
- Conecte o Raspberry Pi a uma fonte de energia, monitor, teclado e Internet.
- Ative o SSH para acesso remoto (opcional, mas recomendado).
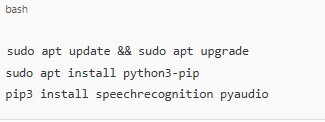
Passo 2: Instale as dependências necessárias
Execute o seguinte comando para atualizar o sistema:
Passo 3: Configure e teste seu microfone
Para capturar a entrada de voz, conecte um microfone USB e verifique se o Raspberry Pi o detecta:
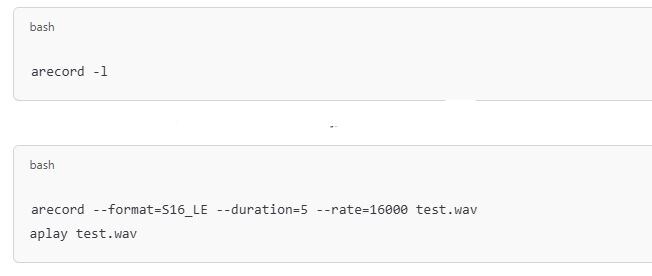
Se você ouvir sua voz gravada, seu microfone está funcionando corretamente.
Passo 4: Instale e configure uma biblioteca de reconhecimento de fala
Existem várias bibliotecas que você pode usar para conversão de fala para texto no Raspberry Pi:
Opção 1: CMU Sphinx (Reconhecimento de Fala Offline)
Para o CMU Sphinx, instale-o usando: pip3 install pocketsphinx
Opção 2: API de Conversão de Fala para Texto do Google (Online e alta precisão)
Execute o seguinte script Python para testar o reconhecimento de fala do Google:

Salve isso como speech_test.py e execute:

Passo 5: Executando e testando o reconhecimento de fala
Agora que você instalou o software necessário e configurou seu microfone, teste sua configuração falando no microfone. O sistema deve converter sua fala em texto e exibi-lo na tela.
Passo 6: Automatizando o reconhecimento de fala no Raspberry Pi
Para fazer com que o reconhecimento de voz do seu Raspberry Pi funcione continuamente:
- Crie um script Python que seja executado na inicialização.
- Use tarefas cron ou serviços systemd para automatizar a execução de conversão de fala em texto.
Example cron job:
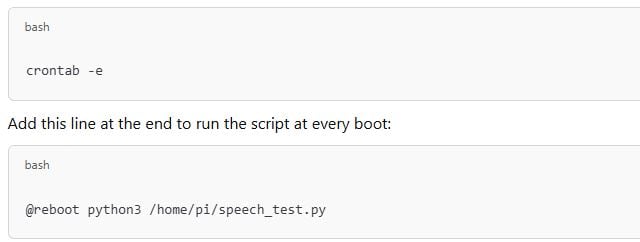
Parte 3. Desafios e limitações no reconhecimento de fala do Raspberry Pi
Embora o reconhecimento de fala com Raspberry Pi seja uma maneira acessível de experimentar o reconhecimento de fala, seu desempenho não está no mesmo nível de assistentes de voz de nível comercial, como Google Assistant ou Amazon Alexa. Os usuários frequentemente enfrentam obstáculos técnicos, problemas de precisão e atrasos no processamento em tempo real. Nesta seção, discutiremos suas limitações.
- Poder de processamento limitado
- O Raspberry Pi tem uma CPU mais fraca em comparação a computadores de tamanho normal, o que o torna mais lento no processamento de entrada de voz, especialmente para aplicativos em tempo real. Executar modelos baseados em aprendizado profundo, como o DeepSpeech, pode causar atrasos e atrasos. - Problemas de qualidade de áudio
A qualidade do microfone afeta a precisão. Microfones embutidos ou microfones USB de baixa qualidade podem resultar em entrada de áudio pouco nítida. Além disso, o ruído de fundo afeta o reconhecimento. Ao contrário dos assistentes de voz comerciais, o Raspberry Pi não possui cancelamento de ruído avançado.
- Reconhecimento offline vs. baseado em nuvem
Ferramentas de reconhecimento offline (CMU Sphinx, Vosk) têm menor precisão do que soluções baseadas em nuvem, como o Google Speech API. APIs baseadas em nuvem oferecem maior precisão, mas exigem uma conexão de Internet estável, o que limita a usabilidade offline.
- Latência e tempo de resposta lento
O reconhecimento de fala não é instantâneo: o processamento leva mais tempo em comparação aos assistentes de voz com tecnologia de IA. O Raspberry Pi tem dificuldade para lidar com vários comandos de voz rapidamente, o que o torna menos prático para aplicações em tempo real.
Parte 4. Alternativa mais fácil com alta precisão e sem requisitos técnicos: Filmora
Embora o reconhecimento de fala do Raspberry Pi seja uma opção poderosa para entusiastas de tecnologia, ele requer configuração manual, conhecimento de codificação e solução de problemas ocasionais. Se você procura uma solução mais rápida, precisa e sem complicações, o Wondershare Filmora é a alternativa perfeita.
Filmora é um software de edição de vídeo que vem com ferramentas integradas de reconhecimento de fala com tecnologia de IA, tornando a edição baseada em voz muito fácil. Ao contrário das configurações de conversão de voz em texto do Raspberry Pi, que podem ter dificuldades com precisão e ruído de fundo, o Filmora oferece transcrições altamente precisas sem exigir configurações complexas ou bibliotecas externas.
Oferece uma experiência perfeita com duas ferramentas principais para conversão de fala em texto e edição baseada em voz:
- Recurso de conversão de fala em texto (Computador): Converte automaticamente palavras faladas em legendas e legendas precisas.
- Recurso de detecção de locutor e edição de fala (Celular): identifica diferentes locutores em um vídeo e permite modificações fáceis na fala com base em texto.
Esses recursos garantem maior precisão, eficiência de tempo e uma experiência intuitiva em comparação com a configuração manual do Raspberry Pi. Na próxima parte, exploraremos como usar essas ferramentas para reconhecimento de fala e edição no Filmora.
- Imensos efeitos de vídeo/áudio e ativos criativos.
- IA poderosa para criação de conteúdo sem esforço.
- Intuitivo, profissional e ainda assim fácil para iniciantes.
- Funciona em Mac, Windows, iOS e Android.



Como usar o recurso de Conversão de Fala para Texto na versão para computador do Filmora
Para usar o recurso de conversão de fala para texto do Filmora no computador, o processo envolve vários passos importantes:
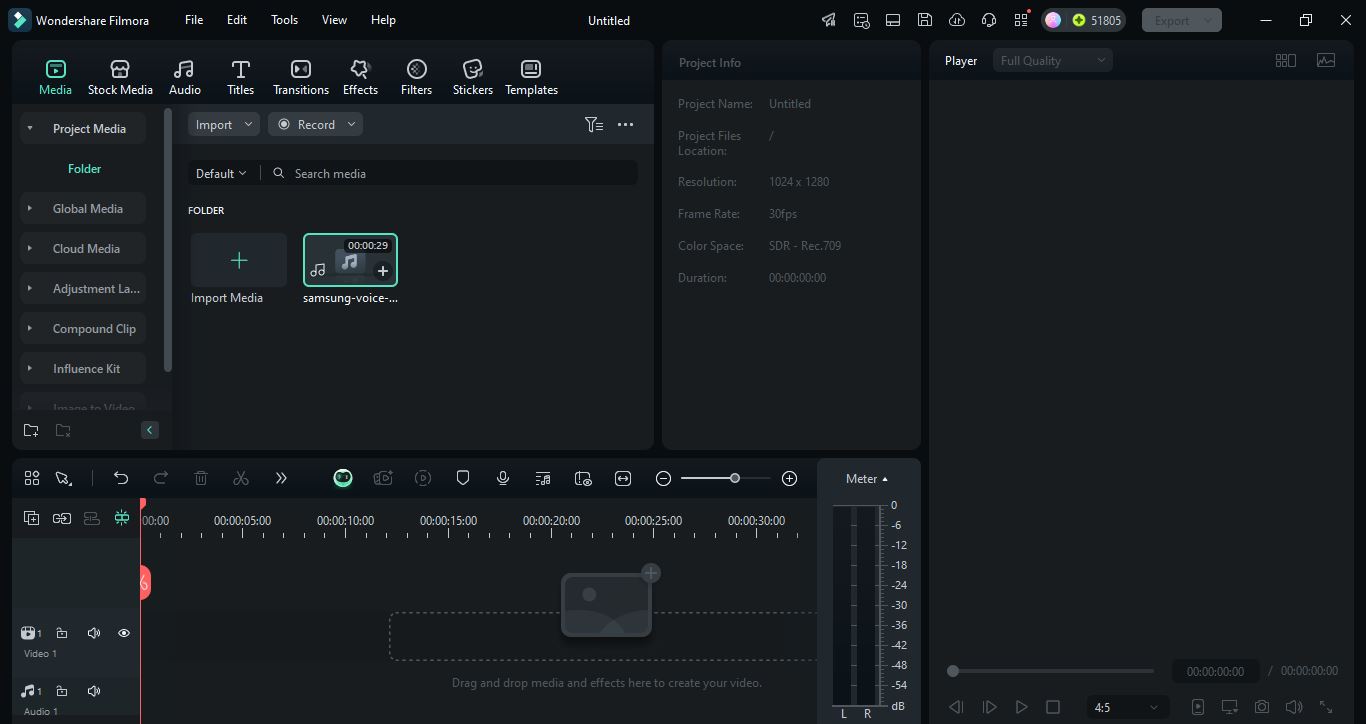
Passo 1. Baixe e instale o software Filmora no seu computador. Abra-o Clique em Novo Projeto e importe seu arquivo de áudio ou vídeo.

 transferência segura
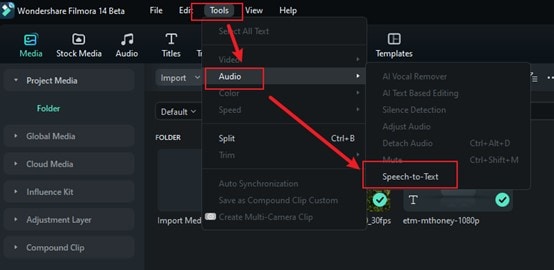
transferência segura Passo 2. Depois que seu arquivo de áudio for importado, arraste-o para a linha do tempo. Para usar a ferramenta de Conversão de Fala para Texto, vá em Ferramentas > Áudio > opção de Conversão de Fala para Texto. Clique no botão de conversão de fala em texto para começar a usar o reconhecimento de fala e convertê-lo em texto
Passo 3. Defina sua preferência de idioma para qualquer idioma que você desejar. Para que a transcrição permaneça no idioma original, clique em “Sem Tradução” para que ela permaneça a mesma. Clique em Gerar para começar e aguarde a conclusão da transcrição, então você poderá salvar o arquivo.
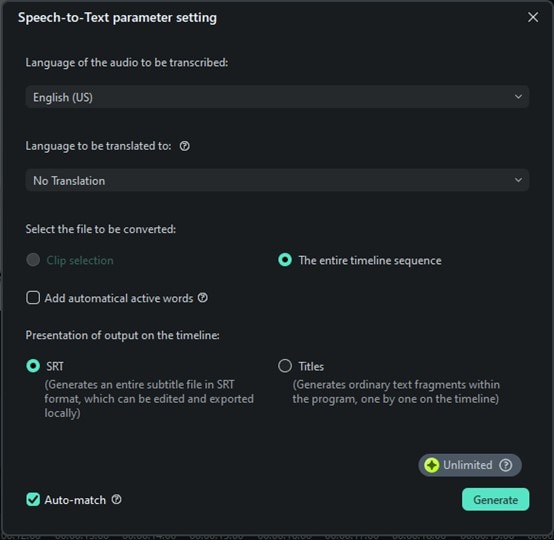
Passo 4. O processamento levará algum tempo e então o arquivo de texto será gerado automaticamente. Você pode editar o arquivo como achar melhor. Clique no arquivo de texto, selecione Exportar arquivo de legenda e escolha o local para salvá-lo. Pronto, sua conversão de fala para texto está pronta com o Filmora.
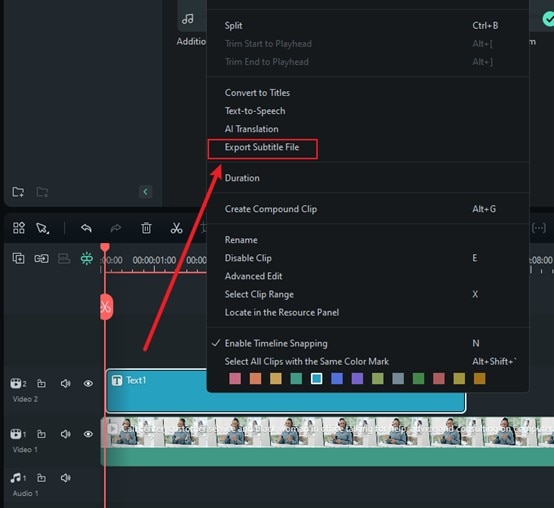
Reconhecer voz automaticamente usando a detecção de alto-falante do Filmora no celular
Usando o recurso de detecção de locutor do Filmora em um dispositivo móvel, você pode identificar vozes automaticamente seguindo estas instruções:
Passo 1. Baixe o aplicativo Filmora mais recente no seu dispositivo, abra-o e clique em Novo Projeto para iniciar.
 transferência segura
transferência segura Passo 2. Escolha o arquivo de vídeo que deseja editar e clique em Importar.

Passo 3. Navegue até o menu inferior, toque em Texto (representado por um ícone "T") e selecione Legendas de IA.
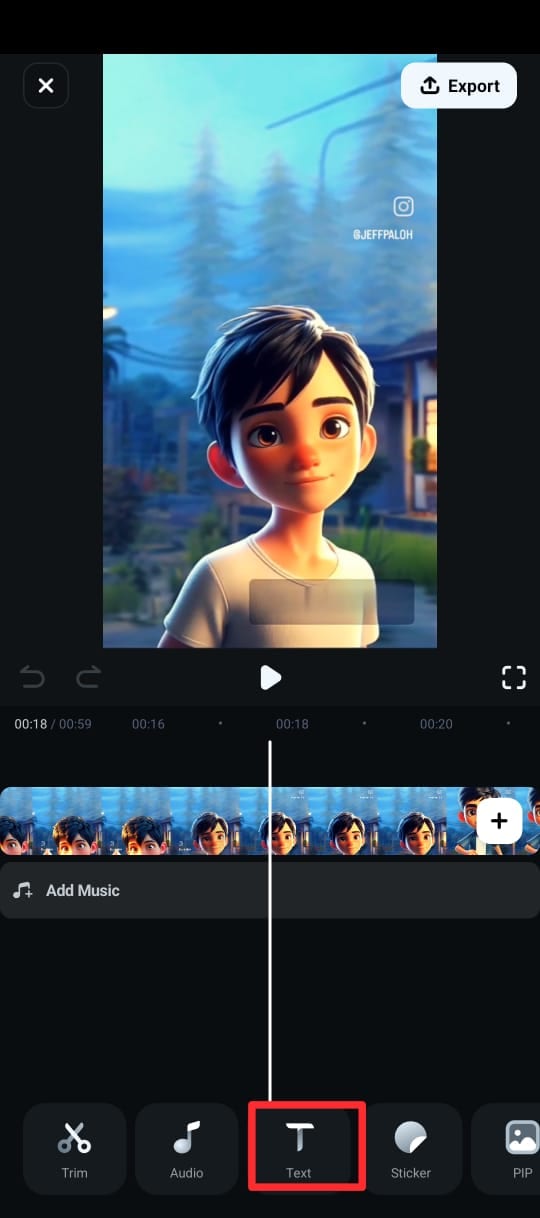
Passo 4: Na próxima tela:
- Selecione o idioma do discurso.
- Ative a Detecção de Locutor (se necessário).
- Toque em Adicionar Legendas para gerar texto a partir do áudio do vídeo.
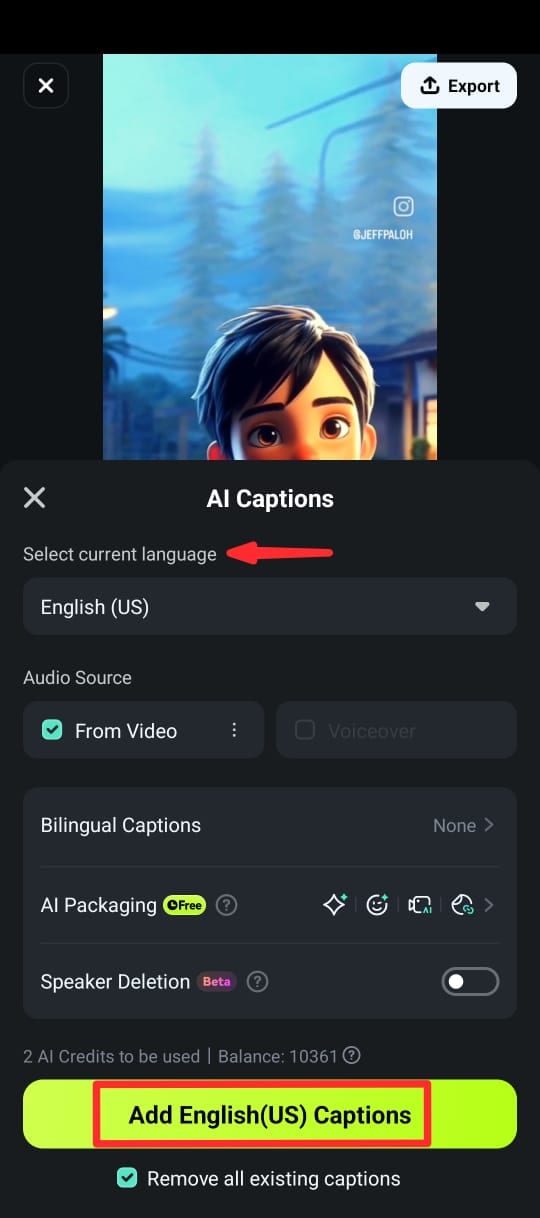
Passo 5. Depois que as legendas forem geradas, você pode:
- Escolha entre vários modelos de texto, fontes e emojis.
- Edite o texto diretamente na linha do tempo selecionando Editar Fala no conjunto de edição.
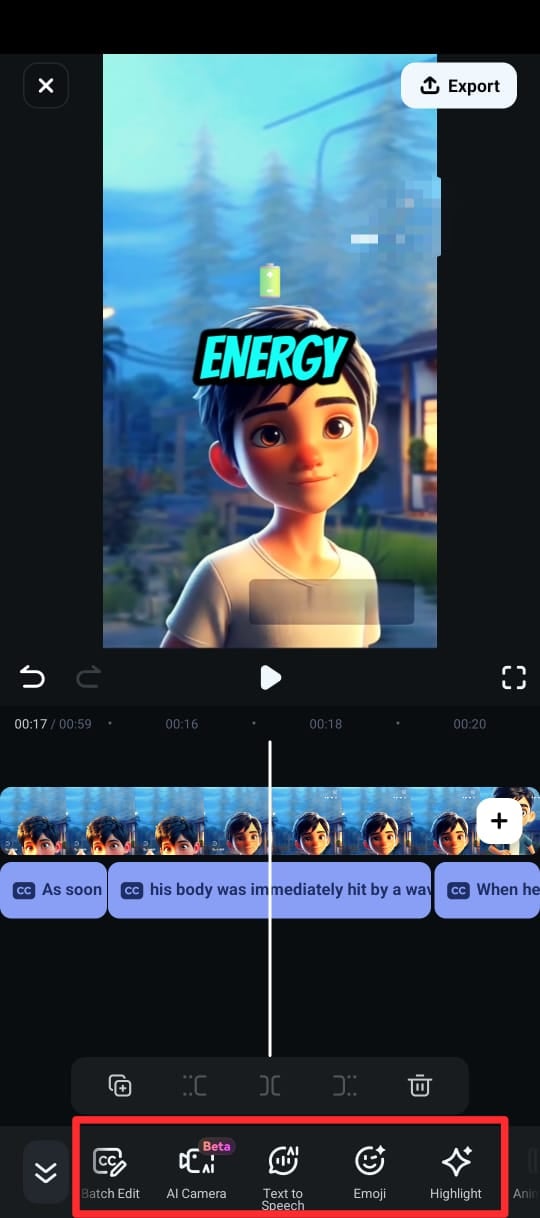
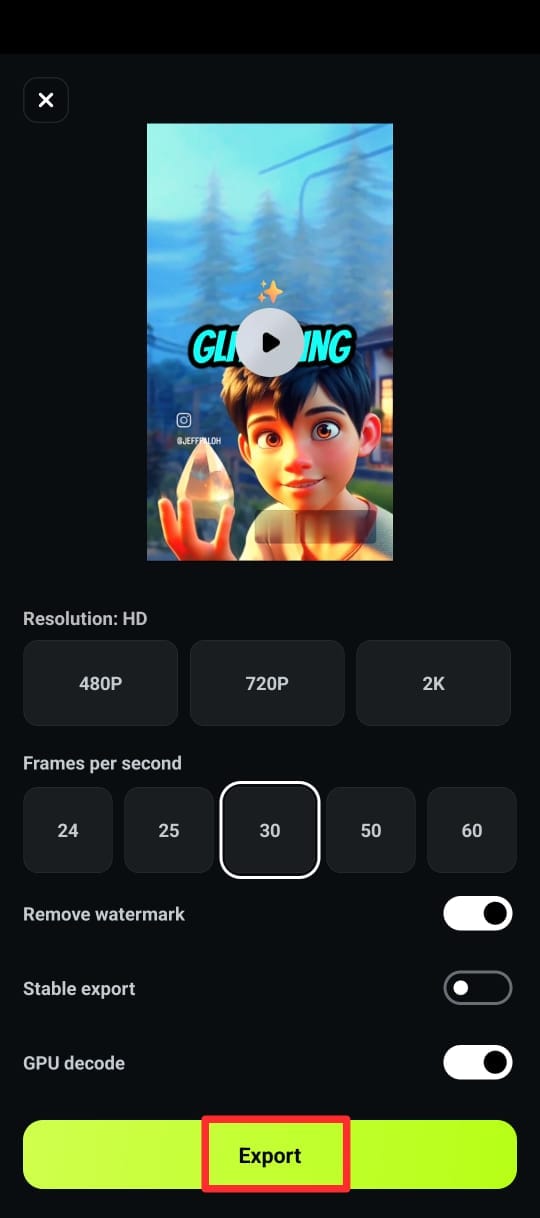
Passo 6. Quando estiver satisfeito com as legendas, exporte seu vídeo no formato e resolução desejados.
Conclusão
O reconhecimento de fala do Raspberry Pi é uma plataforma excelente com uma variedade de alternativas de software, porém tem limitações em precisão e capacidade de processamento. Para usuários que preferem uma experiência simples, as ferramentas de Conversão de Fala para Texto e Detecção de Locutor do Filmora oferecem uma opção para transcrição e edição de áudio fáceis. O Filmora permite simplificar o trabalho baseado em voz sem exigir configurações sofisticadas, o que o torna uma excelente opção para criadores de conteúdo e profissionais.
transferência segura